Keywords


 5'25", 30Mb
5'25", 30Mb 

 2'25", 34Mb
2'25", 34Mb 
 3'09", 20Mb
3'09", 20Mb  7'19", 28Mb
7'19", 28Mb 


Data quality is critical for many information-intensive applications. One of the best opportunities to improve data quality is during entry. Usher provides a theoretical, data-driven foundation for improving data quality during entry. Based on prior data, Usher learns a probabilistic model of the dependencies between form questions and values. Using this information, Usher maximizes information gain. By asking the most unpredictable questions first, Usher is better able to predict answers for the remaining questions. In this paper, we use Usher's predictive ability to design a number of intelligent user interface adaptations that improve data entry accuracy and efficiency. Based on an underlying cognitive model of data entry, we apply these modifications before, during and after committing an answer. We evaluated these mechanisms with professional data entry clerks working with real patient data from six clinics in rural Uganda. The results show that our adaptations have the potential to reduce error (by up to 78%), with limited effect on entry time (varying between -14% and +6%). We believe this approach has wide applicability for improving the quality and availability of data, which is increasingly important for decision-making and resource allocation.



 1'31", 7Mb
1'31", 7Mb In this paper we present a novel interface for selecting sounds in audio mixtures. Traditional interfaces in audio editors provide a graphical representation of sounds which is either a waveform, or some variation of a time/frequency transform. Although with these representations a user might be able to visually identify elements of sounds in a mixture, they do not facilitate object-specific editing (e.g. selecting only the voice of a singer in a song). This interface uses audio guidance from a user in order to select a target sound within a mixture. The user is asked to vocalize (or otherwise sonically represent) the desired target sound, and an automatic process identifies and isolates the elements of the mixture that best relate to the user's input. This way of pointing to specific parts of an audio stream allows a user to perform audio selections which would have been infeasible otherwise.




 2'12", 15Mb
2'12", 15Mb We describe a unique form of hands-free interaction that can be implemented on most commodity computing platforms. Our approach supports blowing at a laptop or computer screen to directly control certain interactive applications. Localization estimates are produced in real-time to determine where on the screen the person is blowing. Our approach relies solely on a single microphone, such as those already embedded in a standard laptop or one placed near a computer monitor, which makes our approach very cost-effective and easy-to-deploy. We show example interaction techniques that leverage this approach.


Because functional near-infrared spectroscopy (fNIRS) eases many of the restrictions of other brain sensors, it has potential to open up new possibilities for HCI research. From our experience using fNIRS technology for HCI, we identify several considerations and provide guidelines for using fNIRS in realistic HCI laboratory settings. We empirically examine whether typical human behavior (e.g. head and facial movement) or computer interaction (e.g. keyboard and mouse usage) interfere with brain measurement using fNIRS. Based on the results of our study, we establish which physical behaviors inherent in computer usage interfere with accurate fNIRS sensing of cognitive state information, which can be corrected in data analysis, and which are acceptable. With these findings, we hope to facilitate further adoption of fNIRS brain sensing technology in HCI research.
 4'55", 75Mb
4'55", 75Mb 

 2'31", 6Mb
2'31", 6Mb  4'57", 38Mb
4'57", 38Mb  3'21", 15Mb
3'21", 15Mb Attribute gates are a new user interface element designed to address the problem of concurrently setting attributes and moving objects between territories on a digital tabletop. Motivated by the notion of task levels in activity theory, and crossing interfaces, attribute gates allow users to operationalize multiple subtasks in one smooth movement. We present two configurations of attribute gates; (1) grid gates which spatially distribute attribute values in a regular grid, and require users to draw trajectories through the attributes; (2) polar gates which distribute attribute values on segments of concentric rings, and require users to align segments when setting attribute combinations. The layout of both configurations was optimised based on targeting and steering laws derived from Fitts' Law. A study compared the use of attribute gates with traditional contextual menus. Users of attribute gates demonstrated both increased performance and higher mutual awareness.
 1'18", 11Mb
1'18", 11Mb 







Can new interfaces contribute to social and environmental improvement? For all the care, wit and brilliance that UIST innovations can contribute, can they actually make things better - better in the sense of public good - not merely lead to easier to use or more efficient consumer goods? This talk will explore the impact of interface technology on society and the environment, and examine engineered systems that invite participation, document change over time, and suggest alternative courses of action that are ethical and sustainable, drawing on examples from a diverse series of experimental designs and site-specific work Natalie has created throughout her career.

Exertion activities, such as jogging, require users to invest intense physical effort and are associated with physical and social health benefits. Despite the benefits, our understanding of exertion activities is limited, especially when it comes to social experiences. In order to begin understanding how to design for technologically augmented social exertion experiences, we present "Jogging over a Distance", a system in which spatialized audio based on heart rate allowed runners as far apart as Europe and Australia to run together. Our analysis revealed how certain aspects of the design facilitated a social experience, and consequently we describe a framework for designing augmented exertion activities. We make recommendations as to how designers could use this framework to aid the development of future social systems that aim to utilize the benefits of exertion.

 5'29", 66Mb
5'29", 66Mb When the Macintosh first made graphical user interfaces popular the notion of each person having their own computer was novel. Today's technology landscape is characterized by multiple computers per person many with far more capacity than that original Mac. The world of input devices, display devices and interactive techniques is far richer than those Macintosh days. Despite all of this diversity in possible interactions very few of these integrate well with each other. The monolithic isolated user interface architecture that characterized the Macintosh still dominates a great deal of today's personal computing. This talk will explore how possible ways to change that architecture so that information, interaction and communication flows more smoothly among our devices and those of our associates.

 5'05", 27Mb
5'05", 27Mb  6'05", 40Mb
6'05", 40Mb We present EverybodyLovesSketch, a gesture-based 3D curve sketching system for rapid ideation and visualization of 3D forms, aimed at a broad audience. We first analyze traditional perspective drawing in professional practice. We then design a system built upon the paradigm of ILoveSketch, a 3D curve drawing system for design professionals. The new system incorporates many interaction aspects of perspective drawing with judicious automation to enable novices with no perspective training to proficiently create 3D curve sketches. EverybodyLovesSketch supports a number of novel interactions: tick-based sketch plane selection, single view definition of arbitrary extrusion vectors, multiple extruded surface sketching, copy-and-project of 3D curves, freeform surface sketching, and an interactive perspective grid. Finally, we present a study involving 49 high school students (with no formal artistic training) who each learned and used the system over 11 days, which provides detailed insights into the popularity, power and usability of the various techniques, and shows our system to be easily learnt and effectively used, with broad appeal.

 6'44", 63Mb
6'44", 63Mb 






 4'22", 55Mb
4'22", 55Mb  3'55", 47Mb
3'55", 47Mb 
 1'24", 12Mb
1'24", 12Mb  25", 2Mb
25", 2Mb  2'31", 17Mb
2'31", 17Mb 
In this paper, we present a methodology for recognizing seatedpostures using data from pressure sensors installed on a chair.Information about seated postures could be used to help avoidadverse effects of sitting for long periods of time or to predictseated activities for a human-computer interface. Our system designdisplays accurate near-real-time classification performance on datafrom subjects on which the posture recognition system was nottrained by using a set of carefully designed, subject-invariantsignal features. By using a near-optimal sensor placement strategy,we keep the number of required sensors low thereby reducing costand computational complexity. We evaluated the performance of ourtechnology using a series of empirical methods including (1)cross-validation (classification accuracy of 87% for ten posturesusing data from 31 sensors), and (2) a physical deployment of oursystem (78% classification accuracy using data from 19sensors).

In this paper we describe Gilded Gait, a system that changes the perceived physical texture of the ground, as felt through the soles of users' feet. Ground texture, in spite of its potential as an effective channel of peripheral information display, has so far been paid little attention in HCI research. The system is designed as a pair of insoles with embedded actuators, and utilizes vibrotactile feedback to simulate the perceptions of a range of different ground textures. The discreet, low-key nature of the interface makes it particularly suited for outdoor use, and its capacity to alter how people experience the built environment may open new possibilities in urban design.



 4'20", 50Mb
4'20", 50Mb  5'57", 21Mb
5'57", 21Mb SketchWizard allows designers to create Wizard of Oz prototypes of pen-based user interfaces in the early stages of design. In the past, designers have been inhibited from participating in the design of pen-based interfaces because of the inadequacy of paper prototypes and the difficulty of developing functional prototypes. In SketchWizard, designers and end users share a drawing canvas between two computers, allowing the designer to simulate the behavior of recognition or other technologies. Special editing features are provided to help designers respond quickly to end-user input. This paper describes the SketchWizard system and presents two evaluations of our approach. The first is an early feasibility study in which Wizard of Oz was used to prototype a pen-based user interface. The second is a laboratory study in which designers used SketchWizard to simulate existing pen-based interfaces. Both showed that end users gave valuable feedback in spite of delays between end-user actions and wizard updates.

 4'19", 21Mb
4'19", 21Mb  5'00", 32Mb
5'00", 32Mb  3'55", 24Mb
3'55", 24Mb 
 4'45", 44Mb
4'45", 44Mb 


 2'12", 15Mb
2'12", 15Mb We describe a unique form of hands-free interaction that can be implemented on most commodity computing platforms. Our approach supports blowing at a laptop or computer screen to directly control certain interactive applications. Localization estimates are produced in real-time to determine where on the screen the person is blowing. Our approach relies solely on a single microphone, such as those already embedded in a standard laptop or one placed near a computer monitor, which makes our approach very cost-effective and easy-to-deploy. We show example interaction techniques that leverage this approach.

 5'07", 19Mb
5'07", 19Mb 

 7'40", 111Mb
7'40", 111Mb  3'56", 15Mb
3'56", 15Mb  5'40", 76Mb
5'40", 76Mb 

 7'40", 111Mb 3'56", 15Mb 5'57", 21Mb
7'40", 111Mb 3'56", 15Mb 5'57", 21Mb SketchWizard allows designers to create Wizard of Oz prototypes of pen-based user interfaces in the early stages of design. In the past, designers have been inhibited from participating in the design of pen-based interfaces because of the inadequacy of paper prototypes and the difficulty of developing functional prototypes. In SketchWizard, designers and end users share a drawing canvas between two computers, allowing the designer to simulate the behavior of recognition or other technologies. Special editing features are provided to help designers respond quickly to end-user input. This paper describes the SketchWizard system and presents two evaluations of our approach. The first is an early feasibility study in which Wizard of Oz was used to prototype a pen-based user interface. The second is a laboratory study in which designers used SketchWizard to simulate existing pen-based interfaces. Both showed that end users gave valuable feedback in spite of delays between end-user actions and wizard updates.
 4'59", 18Mb
4'59", 18Mb 
 7'21", 92Mb
7'21", 92Mb 

 3'55", 47Mb
3'55", 47Mb 
 4'21", 9Mb
4'21", 9Mb 
 1'40", 15Mb
1'40", 15Mb  3'29", 21Mb
3'29", 21Mb  4'10", 29Mb
4'10", 29Mb 
 2'57", 43Mb
2'57", 43Mb 
 8'09", 138Mb
8'09", 138Mb  2'01", 24Mb 5'40", 76Mb
2'01", 24Mb 5'40", 76Mb  2'39", 30Mb
2'39", 30Mb Previous work has demonstrated the viability of applying offline analysis to interpret forearm electromyography (EMG) and classify finger gestures on a physical surface. We extend those results to bring us closer to using muscle-computer interfaces for always-available input in real-world applications. We leverage existing taxonomies of natural human grips to develop a gesture set covering interaction in free space even when hands are busy with other objects. We present a system that classifies these gestures in real-time and we introduce a bi-manual paradigm that enables use in interactive systems. We report experimental results demonstrating four-finger classification accuracies averaging 79% for pinching, 85% while holding a travel mug, and 88% when carrying a weighted bag. We further show generalizability across different arm postures and explore the tradeoffs of providing real-time visual feedback.
 4'17", 13Mb
4'17", 13Mb 
This paper presents CoCo, a system that automates web tasks on a user's behalf through an interactive conversational interface. Given a short command such as "get road conditions for highway 88," CoCo synthesizes a plan to accomplish the task, executes it on the web, extracts an informative response, and returns the result to the user as a snippet of text. A novel aspect of our approach is that we leverage a repository of previously recorded web scripts and the user's personal web browsing history to determine how to complete each requested task. This paper describes the design and implementation of our system, along with the results of a brief user study that evaluates how likely users are to understand what CoCo does for them.
 1'13", 7Mb
1'13", 7Mb 
The lack of access to visual information like text labels, icons, and colors can cause frustration and decrease independence for blind people. Current access technology uses automatic approaches to address some problems in this space, but the technology is error-prone, limited in scope, and quite expensive. In this paper, we introduce VizWiz, a talking application for mobile phones that offers a new alternative to answering visual questions in nearly real-time - asking multiple people on the web. To support answering questions quickly, we introduce a general approach for intelligently recruiting human workers in advance called quikTurkit so that workers are available when new questions arrive. A field deployment with 11 blind participants illustrates that blind people can effectively use VizWiz to cheaply answer questions in their everyday lives, highlighting issues that automatic approaches will need to address to be useful. Finally, we illustrate the potential of using VizWiz as part of the participatory design of advanced tools by using it to build and evaluate VizWiz::LocateIt, an interactive mobile tool that helps blind people solve general visual search problems.
 3'21", 15Mb
3'21", 15Mb This paper presents Foldable User Interfaces (FUI), a combination of a 3D GUI with windows imbued with the physics of paper, and Foldable Input Devices (FIDs). FIDs are sheets of paper that allow realistic transformations of graphical sheets in the FUI. Foldable input devices are made out of construction paper augmented with IR reflectors, and tracked by computer vision. Window sheets can be picked up and flexed with simple movements and deformations of the FID. FIDs allow a diverse lexicon of one-handed and two-handed interaction techniques, including folding, bending, flipping and stacking. We show how these can be used to ease the creation of simple 3D models, but also for tasks such as page navigation.
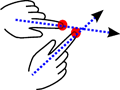
Current interactions on direct-touch interactive surfaces are often modeled based on properties of the input channel that are common in traditional graphical user interfaces (GUI) such as x-y coordinate information. Leveraging additional information available on the surfaces could potentially result in richer and novel interactions. In this paper we specifically explore the role of finger orientation. This property is typically ignored in touch-based interactions partly because of the ambiguity in determining it solely from the contact shape. We present a simple algorithm that unambiguously detects the directed finger orientation vector in real-time from contact information only, by considering the dynamics of the finger landing process. Results of an experimental evaluation show that our algorithm is stable and accurate. We then demonstrate how finger orientation can be leveraged to enable novel interactions and to infer higher-level information such as hand occlusion or user position. We present a set of orientation-aware interaction techniques and widgets for direct-touch surfaces.
 2'59", 10Mb
2'59", 10Mb  3'21", 15Mb
3'21", 15Mb This paper presents Foldable User Interfaces (FUI), a combination of a 3D GUI with windows imbued with the physics of paper, and Foldable Input Devices (FIDs). FIDs are sheets of paper that allow realistic transformations of graphical sheets in the FUI. Foldable input devices are made out of construction paper augmented with IR reflectors, and tracked by computer vision. Window sheets can be picked up and flexed with simple movements and deformations of the FID. FIDs allow a diverse lexicon of one-handed and two-handed interaction techniques, including folding, bending, flipping and stacking. We show how these can be used to ease the creation of simple 3D models, but also for tasks such as page navigation.
 1'24", 12Mb 3'55", 47Mb
1'24", 12Mb 3'55", 47Mb 

 1'41", 8Mb
1'41", 8Mb  5'16", 16Mb
5'16", 16Mb 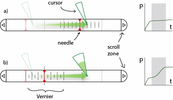 4'21", 22Mb 4'59", 18Mb
4'21", 22Mb 4'59", 18Mb 
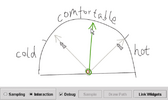 6'34", 22Mb 5'57", 21Mb
6'34", 22Mb 5'57", 21Mb SketchWizard allows designers to create Wizard of Oz prototypes of pen-based user interfaces in the early stages of design. In the past, designers have been inhibited from participating in the design of pen-based interfaces because of the inadequacy of paper prototypes and the difficulty of developing functional prototypes. In SketchWizard, designers and end users share a drawing canvas between two computers, allowing the designer to simulate the behavior of recognition or other technologies. Special editing features are provided to help designers respond quickly to end-user input. This paper describes the SketchWizard system and presents two evaluations of our approach. The first is an early feasibility study in which Wizard of Oz was used to prototype a pen-based user interface. The second is a laboratory study in which designers used SketchWizard to simulate existing pen-based interfaces. Both showed that end users gave valuable feedback in spite of delays between end-user actions and wizard updates.
 3'14", 38Mb
3'14", 38Mb Multi-display environments compose displays that can be at different locations from and different angles to the user; as a result, it can become very difficult to manage windows, read text, and manipulate objects. We investigate the idea of perspective as a way to solve these problems in multi-display environments. We first identify basic display and control factors that are affected by perspective, such as visibility, fracture, and sharing. We then present the design and implementation of E-conic, a multi-display multi-user environment that uses location data about displays and users to dynamically correct perspective. We carried out a controlled experiment to test the benefits of perspective correction in basic interaction tasks like targeting, steering, aligning, pattern-matching and reading. Our results show that perspective correction significantly and substantially improves user performance in all these tasks.
 3'07", 12Mb
3'07", 12Mb 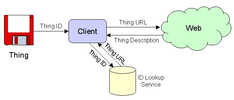

 2'30", 32Mb
2'30", 32Mb 
 1'46", 5Mb
1'46", 5Mb  2'21", 41Mb
2'21", 41Mb  2'53", 21Mb
2'53", 21Mb 
 7'23", 186Mb
7'23", 186Mb  5'59", 22Mb
5'59", 22Mb 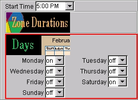 10'48", 198Mb
10'48", 198Mb  4'05", 47Mb
4'05", 47Mb 
 4'12", 51Mb 4'19", 21Mb
4'12", 51Mb 4'19", 21Mb 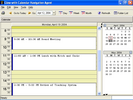 2'54", 21Mb
2'54", 21Mb  3'55", 47Mb
3'55", 47Mb 

PhotoelasticTouch is a novel tabletop system designed to intuitively facilitate touch-based interaction via real objects made from transparent elastic material. The system utilizes vision-based recognition techniques and the photoelastic properties of the transparent rubber to recognize deformed regions of the elastic material. Our system works with elastic materials over a wide variety of shapes and does not require any explicit visual markers. Compared to traditional interactive surfaces, our 2.5 dimensional interface system enables direct touch interaction and soft tactile feedback. In this paper we present our force sensing technique using photoelasticity and describe the implementation of our prototype system. We also present three practical applications of PhotoelasticTouch, a force-sensitive touch panel, a tangible face application, and a paint application.
 4'20", 50Mb
4'20", 50Mb 


 2'33", 48Mb
2'33", 48Mb  3'41", 27Mb
3'41", 27Mb  5'00", 40Mb
5'00", 40Mb We present a system for the actuation of tangible magnetic widgets (Madgets) on interactive tabletops. Our system combines electromagnetic actuation with fiber optic tracking to move and operate physical controls. The presented mechanism supports actuating complex tangibles that consist of multiple parts. A grid of optical fibers transmits marker positions past our actuation hardware to cameras below the table. We introduce a visual tracking algorithm that is able to detect objects and touches from the strongly sub-sampled video input of that grid. Six sample Madgets illustrate the capabilities of our approach, ranging from tangential movement and height actuation to inductive power transfer. Madgets combine the benefits of passive, untethered, and translucent tangibles with the ability to actuate them with multiple degrees of freedom.
 6'39", 39Mb
6'39", 39Mb 

Many patients with paralyzing injuries or medical conditions retain the use of their cranial nerves, which control the eyes, jaw, and tongue. While researchers have explored eye-tracking and speech technologies for these patients, we believe there is potential for directly sensing explicit tongue movement for controlling computers. In this paper, we describe a novel approach of using infrared optical sensors embedded within a dental retainer to sense tongue gestures. We describe an experiment showing our system effectively discriminating between four simple gestures with over 90% accuracy. In this experiment, users were also able to play the popular game Tetris with their tongues. Finally, we present lessons learned and opportunities for future work.
 4'10", 29Mb
4'10", 29Mb 





 5'12", 81Mb
5'12", 81Mb 
 7'52", 59Mb
7'52", 59Mb  4'27", 58Mb
4'27", 58Mb 
 57", 2Mb
57", 2Mb  2'54", 13Mb
2'54", 13Mb Temporal events, while often discrete, also have interesting relationships within and across times: larger events are often collections of smaller more discrete events (battles within wars; artists' works within a form); events at one point also have correlations with events at other points (a play written in one period is related to its performance over a period of time). Most temporal visualisations, however, only represent discrete data points or single data types along a single timeline: this event started here and ended there; this work was published at this time; this tag was popular for this period. In order to represent richer, faceted attributes of temporal events, we present Continuum. Continuum enables hierarchical relationships in temporal data to be represented and explored; it enables relationships between events across periods to be expressed, and in particular it enables user-determined control over the level of detail of any facet of interest so that the person using the system can determine a focus point, no matter the level of zoom over the temporal space. We present the factors motivating our approach, our evaluation and implementation of this new visualisation which makes it easy for anyone to apply this interface to rich, large-scale datasets with temporal data.

Progress bars are prevalent in modern user interfaces. Typically, a linear function is employed such that the progress of the bar is directly proportional to how much work has been completed. However, numerous factors cause progress bars to proceed at non-linear rates. Additionally, humans perceive time in a non-linear way. This paper explores the impact of various progress bar behaviors on user perception of process duration. The results are used to suggest several design considerations that can make progress bars appear faster and ultimately improve users' computing experience.

Although mobile, tablet, large display, and tabletop computers increasingly present opportunities for using pen, finger, and wand gestures in user interfaces, implementing gesture recognition largely has been the privilege of pattern matching experts, not user interface prototypers. Although some user interface libraries and toolkits offer gesture recognizers, such infrastructure is often unavailable in design-oriented environments like Flash, scripting environments like JavaScript, or brand new off-desktop prototyping environments. To enable novice programmers to incorporate gestures into their UI prototypes, we present a "$1 recognizer" that is easy, cheap, and usable almost anywhere in about 100 lines of code. In a study comparing our $1 recognizer, Dynamic Time Warping, and the Rubine classifier on user-supplied gestures, we found that $1 obtains over 97% accuracy with only 1 loaded template and 99% accuracy with 3+ loaded templates. These results were nearly identical to DTW and superior to Rubine. In addition, we found that medium-speed gestures, in which users balanced speed and accuracy, were recognized better than slow or fast gestures for all three recognizers. We also discuss the effect that the number of templates or training examples has on recognition, the score falloff along recognizers' N-best lists, and results for individual gestures. We include detailed pseudocode of the $1 recognizer to aid development, inspection, extension, and testing.

Tactile feedback allows devices to communicate with users when visual and auditory feedback are inappropriate. Unfortunately, current vibrotactile feedback is abstract and not related to the content of the message. This often clash-es with the nature of the message, for example, when sending a comforting message.
We propose addressing this by extending the repertoire of haptic notifications. By moving an actuator perpendicular to the user's skin, our prototype device can tap the user. Moving the actuator parallel to the user's skin induces rub-bing. Unlike traditional vibrotactile feedback, tapping and rubbing convey a distinct emotional message, similar to those induced by human-human touch.
To enable these techniques we built a device we call soundTouch. It translates audio wave files into lateral motion using a voice coil motor found in computer hard drives. SoundTouch can produce motion from below 1Hz to above 10kHz with high precision and fidelity.
We present the results of two exploratory studies. We found that participants were able to distinguish a range of taps and rubs. Our findings also indicate that tapping and rubbing are perceived as being similar to touch interactions exchanged by humans.

 3'21", 15Mb
3'21", 15Mb Attribute gates are a new user interface element designed to address the problem of concurrently setting attributes and moving objects between territories on a digital tabletop. Motivated by the notion of task levels in activity theory, and crossing interfaces, attribute gates allow users to operationalize multiple subtasks in one smooth movement. We present two configurations of attribute gates; (1) grid gates which spatially distribute attribute values in a regular grid, and require users to draw trajectories through the attributes; (2) polar gates which distribute attribute values on segments of concentric rings, and require users to align segments when setting attribute combinations. The layout of both configurations was optimised based on targeting and steering laws derived from Fitts' Law. A study compared the use of attribute gates with traditional contextual menus. Users of attribute gates demonstrated both increased performance and higher mutual awareness.
 9'26", 95Mb
9'26", 95Mb 

 9'52", 85Mb
9'52", 85Mb 
 4'46", 38Mb 5'05", 27Mb
4'46", 38Mb 5'05", 27Mb  9'26", 95Mb
9'26", 95Mb 











The development of user interface systems has languished with the stability of desktop computing. Future systems, however, that are off-the-desktop, nomadic or physical in nature will involve new devices and new software systems for creating interactive applications. Simple usability testing is not adequate for evaluating complex systems. The problems with evaluating systems work are explored and a set of criteria for evaluating new UI systems work is presented.

 6'44", 63Mb
6'44", 63Mb 
 2'30", 32Mb
2'30", 32Mb 
 4'51", 105Mb
4'51", 105Mb  1'51", 29Mb
1'51", 29Mb  3'05", 17Mb
3'05", 17Mb Studies of search habits reveal that people engage in many search tasks involving collaboration with others, such as travel planning, organizing social events, or working on a homework assignment. However, current Web search tools are designed for a single user, working alone. We introduce SearchTogether, a prototype that enables groups of remote users to synchronously or asynchronously collaborate when searching the Web. We describe an example usage scenario, and discuss the ways SearchTogether facilitates collaboration by supporting awareness, division of labor, and persistence. We then discuss the findings of our evaluation of SearchTogether, analyzing which aspects of its design enabled successful collaboration among study participants.

Programmers regularly use search as part of the development process, attempting to identify an appropriate API for a problem, seeking more information about an API, and seeking samples that show how to use an API. However, neither general-purpose search engines nor existing code search engines currently fit their needs, in large part because the information programmers need is distributed across many pages. We present Assieme, a Web search interface that effectively supports common programming search tasks by combining information from Web-accessible Java Archive (JAR) files, API documentation, and pages that include explanatory text and sample code. Assieme uses a novel approach to finding and resolving implicit references to Java packages, types, and members within sample code on the Web. In a study of programmers performing searches related to common programming tasks, we show that programmers obtain better solutions, using fewer queries, in the same amount of time spent using a general Web search interface.
 3'48", 16Mb
3'48", 16Mb 

 3'54", 182Mb
3'54", 182Mb